Investing in resilience – Where data centers are placing their bets next

IT leaders aren’t just talking about reliability and modernization – they’re putting money behind it. In a recent survey by Futurum Research, in partnership with Nokia, organizations were asked what their top investment priorities are for improving data center reliability in the next year. The answers echo all the themes we’ve discussed: automation, resilience and modernization. In this final post of our series, we’ll break down where enterprises are focusing their next round of improvements. Consider it a roadmap for a future-ready infrastructure: from advanced automation tools and incident response plans to ripping out legacy hardware, these are the areas getting the attention (and budget) of CIOs and data center operators.
Top priorities: Automation, rapid recovery, modernization
When asked to select their top three initiatives (see Figure 1) for the coming year, respondents delivered a clear message. The #1 planned investment (cited by 50% of respondents) is implementing AI-driven automation tools to reduce manual mistakes. Half of all surveyed organizations are prioritizing spending on things like network automation platforms, AIOps analytics, or orchestration frameworks – anything that can cut down human error and speed up operations. This aligns perfectly with the overarching theme we’ve seen: automation is viewed as the key to reliability. Enterprise IT teams are essentially saying, “We intend to buy or build smarter tools so our data center can run with fewer hiccups.”
The second-highest priority (42% of respondents) is improving incident response and recovery capabilities. While the first priority is about preventing outages, this one is about mitigating impact when incidents do happen. Companies are recognizing that despite all prevention, things can still go wrong – and what matters is how quickly you can bounce back. Investments here might include better incident management software, more robust disaster recovery (DR) plans, conducting regular drills or simulations and refining runbooks so that IT teams can respond swiftly under pressure. Interestingly, alongside this, about 25% of organizations said they will “tighten change governance” – in other words, improve change control processes, approvals and oversight as part of their reliability strategy. That makes sense: change management is often where incidents originate, so stricter governance can prevent some outages in the first place. Together, the focus on incident response and change governance shows an emphasis on operational resilience – both reactive and proactive.
The third major initiative (40% of respondents) is full infrastructure modernization or tech refresh. Many organizations are planning to upgrade their data center hardware and software wholesale. This could mean moving more workloads to cloud or new colocation facilities, deploying a new high-speed network fabric, or replacing aging servers and network gear with state-of-the-art equipment. The logic is simple: outdated technology can be a liability for reliability, so it’s better to modernize than to nurse along legacy systems. Recall that earlier in the survey, a quarter of respondents flagged “too much legacy tech” as a barrier to reliability. Now we see the response to that – rip out the old stuff. In fact, 27% specifically plan to replace or upgrade hardware (servers, network devices, power systems) to ensure their infrastructure is less failure-prone and supports modern features. Newer hardware often brings better redundancy, telemetry and automation hooks that help with reliability, so this investment can pay off in both fewer outages and easier management.
Figure 1. If you were to invest in three initiatives to improve your reliability posture next year, what would they be?
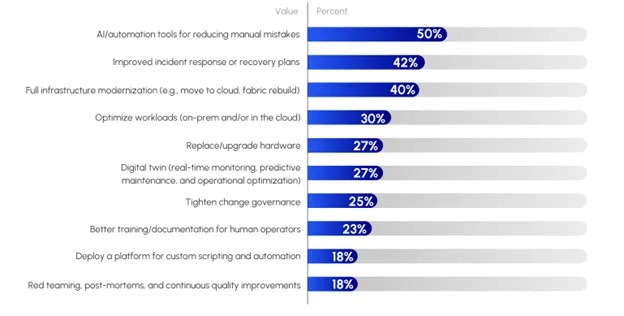
Source: The Data Center Network Imperative: Key Trends Driving the Next Era of Data Centers, Futurum Research,
September 2025.
Rounding out the roadmap: Optimization, digital twins and training
Beyond the top three, several other initiatives are noteworthy. Optimizing workload placement across on-prem and cloud environments (selected by 30%) is a priority for about a third of organizations. This is about smart architecture – ensuring that each application or service runs in the most suitable environment for resilience and performance. It could involve shifting some workloads to cloud for better redundancy, or conversely repatriating others on-prem if that offers more control. The key is to avoid having all your eggs in one basket and to use each environment’s strengths to your advantage.
Another 27% plan to implement a network digital twin for real-time monitoring, predictive maintenance and testing. We discussed digital twins earlier: a virtual replica of your data center network that you can experiment on safely. Investing in this indicates a desire to catch problems before they occur – by simulating changes or running “what-if” scenarios in the twin, you can prevent misconfigurations and forecast capacity issues. It’s a very forward-looking strategy to improve reliability and efficiency.

Interestingly, 23% of respondents are prioritizing better training and documentation for their human operators as a key investment area. This ties directly back to the previous post about skill gaps. Companies realize that buying fancy tools isn’t enough; you also need to upskill your team to use those tools effectively and follow best practices. Allocating budget to training programs, documentation projects, or perhaps hiring new talent shows that people remain a core part of the resilience equation. As one might say, a fool with a tool is still a fool – so training ensures your staff can leverage new tech properly (and avoid errors).
A smaller but notable slice (18%) are looking to deploy platforms for custom scripting and automation – essentially building internal tools or self-service automation platforms to address their unique needs. Another 18% cite red teaming, post-mortems and continuous quality improvements as priorities. These may be lower percentages, but they’re the mark of more mature operations that are institutionalizing the practice of continuous improvement. Red teaming (simulating failures or attacks) and thorough post-incident reviews help organizations learn and improve over time. They complement the top priorities by ensuring that even after new systems are implemented, the organization keeps refining its resilience through practice and feedback loops.
What’s important is that even these “lower ranked” initiatives support the bigger goals. For example, doing regular post-mortems will make your incident response (the #2 priority) more effective over time. Developing a custom automation platform might feed into your broader automation push (#1 priority). The survey analysis noted that all these initiatives work in concert: modernize tech, automate ops, prepare for failures and equip people with the right skills/processes. It’s a holistic approach to reliability.
Resilience through automation and modernization
Considering all the planned investments together, a unified theme emerges: Enterprises are striving for “resilience through modernization and automation.” They’re envisioning data centers that can heal themselves and adapt on the fly – using AI to catch issues early, automation to execute changes flawlessly and modern infrastructure to eliminate brittle, failure-prone components. At the same time, they aren’t forgetting the human element: there’s emphasis on training teams, refining processes and planning for worst-case scenarios so that when disruptions occur, recovery is swift. In essence, the winning formula is technology plus teamwork.
From a strategic perspective, this balanced investment approach is wise. A CIO looking at these results might conclude: “We should budget for advanced automation software and schedule more incident response drills; invest in new hardware and maybe hire a network reliability engineer.” The survey data validates that both sides of the coin matter. For vendors or solution providers reading this, it’s a hint that positioning your product as part of a “resilient infrastructure toolkit” will resonate. If you can show that adopting your solution leads to tangible reliability gains – fewer outages, faster recoveries, smoother migrations – you’re speaking the language that IT execs are listening for.
What’s the major theme?
Enterprises are putting their money where the problems are: automation, reliability and modernization initiatives. If you’re an IT decision-maker, take a cue from these trends. Ensure your upcoming budgets align with reliability goals – this might mean approving that AIOps pilot, allocating funds for a network refresh, or expanding your training programs. The survey suggests that those who invest smartly in these areas will pull ahead in uptime and agility. Consider kicking off a pilot project in a cutting-edge area like AI-driven operations or digital twin technology to stay ahead of the curve. These exploratory projects can yield big dividends in understanding how new tech fits into your environment.
For those on the enterprise side, also look at your current pain points: if human error is causing issues, maybe prioritize an automation tool or an employee training initiative. If legacy systems are a headache, plan that tech refresh sooner rather than later. The data center is rapidly evolving and being proactive is key. As the survey conclusion put it, the industry is shifting from traditional manual operations to a more autonomous, resilient paradigm. Embracing that shift – by investing in both cutting-edge tools and the people who use them – is the way to build an “always-on” data center that can meet the digital business demands of tomorrow.
In summary, the future-ready data center will likely feature self-healing networks, predictive analytics preventing failures and seamless hybrid cloud integration. Getting there requires starting now. So, take a hard look at your roadmap: are you funding the initiatives that will make your infrastructure more robust and intelligent? The leading companies are, and they expect those investments to pay off in fewer outages, greater efficiency and more confidence in their IT backbone. The race to resilience is on – and with the right investments, your organization can cross the finish line as a winner in uptime, innovation and customer trust.
This blog post is number 5 in a series of 5. To see the other posts, visit this page.
You can also find results from the full study here.





