People, process and pitfalls: Tackling human error and skill gaps in the data center network operations

No matter how much automation we deploy, there’s no getting around the human element of IT operations. People are behind the keyboards – and people make mistakes. In a recent study by Futurum Research, in partnership with Nokia, the results shine a light on this “human factor” in data center reliability. It reveals a bit of a paradox: human error is still a notable source of incidents, yet the solution isn’t simply to eliminate humans via automation (at least, not entirely). Organizations are grappling with skill gaps and cultural approaches to minimize mistakes. In this post, we’ll look at how often human errors come into play, what philosophies IT teams have about preventing (or tolerating) mistakes and how companies are investing in skills and processes to shore up their operational resilience.
Human error: The (persistent) weakest link?
There’s a common saying in IT: “The biggest risk is between the chair and keyboard.” The survey results put this in perspective. When asked how frequently operator or configuration mistakes impact service, virtually no one claimed to be immune – only 1.3% of respondents said human errors never affect their continuity. In other words, nearly 99% acknowledged that at least on rare occasions, an outage or issue has resulted from a manual slip-up. The majority view such incidents as infrequent (41% said errors rarely have impact thanks to safeguards and 40% said occasionally, as in a few notable incidents). However, a significant 17.5% admitted that human errors occur frequently and are among their top causes of disruption. That’s roughly one in six organizations where mistakes by admins or engineers are a leading contributor to downtime – a non-trivial figure.
That said, most teams don’t blame humans for most of their problems. The survey asked what percentage of all reliability issues stem from operational/human mistakes; 57% of respondents estimate that human error accounts for no more than 1/4 of their incidents and another 19% peg it at around a third of incidents. Only a tiny 2% felt that over half of the issues are human-caused. This suggests that while people are a known source of risk, many other factors (hardware failures, software bugs, etc.) also cause outages. In other words, technology fails too – it’s not just humans. This nuanced view is healthy: it means organizations see value in both automation (to eliminate some mistakes) and in building robust systems that assume errors will happen and can withstand them.
Process, automation, or resilience? Differing mindsets on human error
How do IT leaders approach the human factor? The survey presented several philosophies and got a fascinating split of responses. The most common stance (35% of respondents) was “prevent errors through strict process discipline and training” (see Figure 1). These are the folks who believe in rigorous change management, detailed runbooks, checklists and peer reviews—essentially, if people follow the right process and are well-trained, mistakes can be minimized. It’s a very process-centric, human-driven approach to reliability.
Another 28% take a mixed approach, saying “it depends on the system” – they’ll enforce strict processes in some areas while leaning on automation in others. This suggests a pragmatic view: not all systems are equal, so you might trust humans (with good processes) for some tasks, but automate other tasks that are too error prone.
Interestingly, only 12% advocated for eliminating errors primarily via automation. Despite the industry buzz about autonomous networks, relatively few respondents think you can (or should) just automate away all human mistakes. Finally, a notable 25% chose “errors are inevitable – focus on resilience and quick recovery.” This group essentially says, we’re all human, mistakes will happen, so the best strategy is designing systems and procedures that contain the blast radius and restore service fast when someone does screw up. None of the respondents said they have “no philosophy” on this – everyone has some stance, which shows awareness of the issue is universal.
Figure 1. Which statement best matches your operational mindset toward the impact of human error on network reliability?
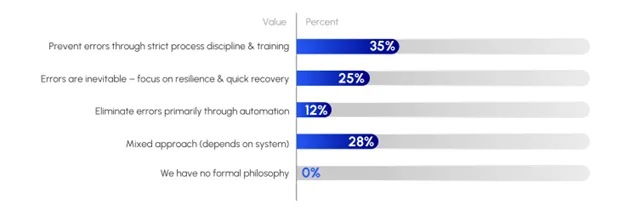
Source: The Data Center Network Imperative: Key Trends Driving the Next Era of Data Centers, Futurum Research,
September 2025.
The distribution of philosophies tells us that many organizations still put a lot of faith in human expertise and process rigor. Culturally, there’s an understanding that while automation helps, you can’t rely on it for everything. Humans remain at the controls and thus training, process discipline and a forgiving infrastructure (that can tolerate errors) are key. Forward-thinking teams often implement things like blameless post-mortems when an error occurs – focusing on fixing the process rather than shaming the individual – and invest in redundancy so one mistake doesn’t lead to catastrophe.
Mind the skills gap: Barriers to automation
One reason automation hasn’t completely taken over may be that it’s easier said than done. A striking finding: the #1 internal impediment to achieving network automation goals is a lack of necessary skills, cited by 54% of respondents. In short, there’s a skills gap. Network engineers are being asked to program, script and leverage DevOps tools – competencies that traditional infrastructure teams haven’t needed in the past. Many enterprises are finding that their talent pool needs an upgrade (or additional training) to fully embrace automation.
Beyond skills, there are other challenges too. 46% of companies said an “inability to monitor current state vs. defined state” of the network is holding back automation efforts. This speaks to tooling and visibility: if you can’t easily compare how the network is supposed to be (the intended configurations) versus how it actually is at any moment, it’s hard to automate safely. Additionally, 44% reported lacking adequate test environments that mirror production – they don’t have “digital twin” labs to trial changes in, which makes them hesitant to automate large-scale changes. And 39% said they lack tools that guarantee safe operations (like transaction consistency or automated validations). All these are essentially gaps in the toolkit or environment that make automation risky. On the bright side, 16% of organizations said “nothing” is impeding their automation – likely those who have invested well in both people and technology and are reaping the benefits.
Broadly speaking, companies also face resource constraints that indirectly affect operations. Budget limitations (24%), regulatory complexity (26%) and having too much legacy tech (22%) were mentioned among the barriers to improving data center reliability. And 13% pointed out that their teams are simply overworked – too busy fighting fires to focus on improvements. These factors all tie back to the human side: you need enough people with the right skills, time and support to drive reliability initiatives.
Strengthening the human element

So, what are organizations doing about it? One immediate step is doubling down on training and process improvements. The survey found that 35% of companies are actively emphasizing stricter process discipline and training to prevent mistakes (many of these are likely the same folks from the philosophy question). In practice, that could mean more frequent training sessions, updated documentation, or enforcing change management policies more rigorously. Additionally, 23% plan to invest in better training and documentation for their teams in the coming year as a key initiative. This was listed among the reliability investments, right alongside technology upgrades, which shows a recognition that people and process are part of the reliability equation (not just new gadgets).
Another trend is hiring or upskilling for new roles – for example, some organizations are bringing on network automation engineers or retraining network admins with Python scripting skills. Partnerships with vendors for workshops or certification programs can also help bridge the gap. The goal is to cultivate an “automation-first, but people-powered” culture: automate what you can and for what you can’t, make sure your staff are well-prepared and following best practices.
Lastly, companies are working to foster a culture of resilience. That means encouraging practices like peer reviews, post-incident reviews (to learn from mistakes) and designing systems that can be quickly recovered. A noteworthy 25% (as mentioned) focus on resilience and quick recovery as their philosophy – we see this in practice with things like 18% of organizations planning to do more red teaming, post-mortems and continuous quality improvements as formal priorities. This is all about institutionalizing learning and continuous improvement, so that each mistake leads to smarter prevention next time.
The big picture
Human error and skill gaps are challenges that require a balanced response. For IT leaders and data center operators, investing in your people is as important as investing in technology. That could mean training your existing team on automation tools, hiring new talent with software skills, or partnering with consultants to accelerate knowledge transfer. It also means putting process guardrails in place – things like automated checklists, change approval workflows and robust documentation – to catch mistakes before they cause havoc. And importantly, cultivate a culture that treats human error as a signal for improvement, not just a blame game. Use errors as learning opportunities to strengthen processes or justify automation investments.
From the survey, it’s clear that the best approach is a combo of human and machine: leverage automation where it makes sense, but also ensure your people are following best practices and prepared to respond when things go wrong. Check if your organization has a formal stance on human error (it likely does, even informally). If not, start that conversation. Encourage blameless post-mortems and ask your team what tools or training they need to do their jobs better. With the right skills and mindset, your team can turn the “weakest link” into one of your greatest assets. After all, even the smartest AI ops tool needs smart people to implement and oversee it. By empowering your staff and addressing skill gaps, you’ll build a more resilient operation that can handle both machine and human glitches with aplomb.
This blog post is number 4 in a series of 5. To see the other posts, visit this page.
You can also find results from the full study here.




