Scale-across networking: Unlocking AI factory scale with optical innovation

At the 2026 Optica Executive Forum and OFC event in Los Angeles, scaling was a central theme. From networks and data centers to advanced computing and XPU (GPU or TPU) clusters and optical supply chains, the industry discussed how to meet rapidly growing demands for AI infrastructure. Panels and presentations explored a range of scaling challenges, including a session I moderated titled “Data Center Interconnect and Scale-across Networking Trends, Challenges and Opportunities in the AI Era”. Featuring experts from Meta, Google, Zayo, Lumen Technologies and Nokia, the standing-room-only session delivered valuable insights from leaders across the AI ecosystem. This blog builds on several of those insights.
As AI infrastructure expands, the industry is increasingly focused on three dimensions of XPU cluster scaling: scale up, scale out and, most recently, scale-across.
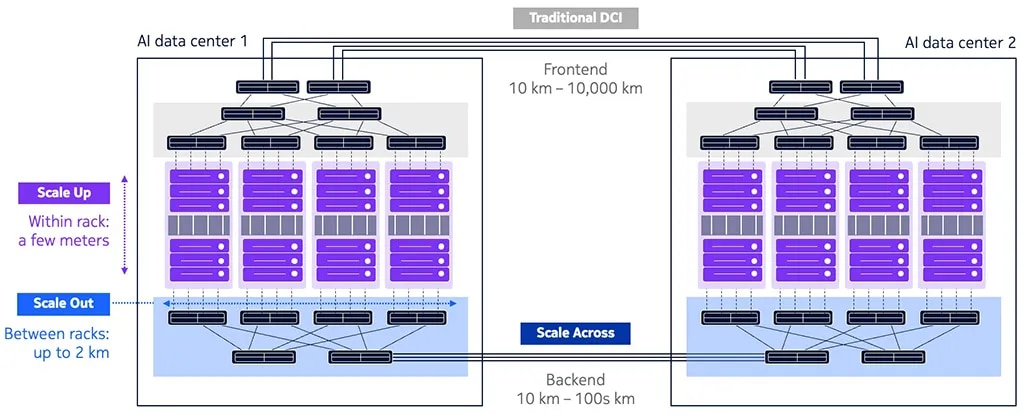
Figure: Three types of data center optical connectivity needed in the AI era - scale up, scale out and scale across.
- Scale-up refers to interconnecting XPUs within a single rack where links are typically only a few meters. Although dominated by copper connectivity today, rising interconnect speeds are driving a transition to optical connectivity for scale-up.
- Scale-out extends cluster connectivity across multiple racks within a data center, most often using direct-detect pluggable optics over distances ranging from hundreds of meters to a few kilometers.
- Scale-across is the newest of these terms. It emerged over the past year, and I’ll define it in some detail below.
Scale-across networking
Scale-across networking is a specialized form of data center interconnect (DCI) for back-end networks that enables an XPU cluster to scale beyond the physical space and power limitations of a single data center. Think of scale-across as scale-out for the WAN – connecting XPUs across tens, hundreds or potentially thousands of kilometers. But even with hundreds of thousands of XPUs per cluster working synchronously, training large language models like GPT, Gemini or Llama on more than a trillion parameters can take weeks or months.
To reduce training times, leading AI and cloud providers are building increasingly larger clusters, with multiple one million XPU clusters planned for 2027. There are, however, significant challenges with acquiring the space and gigawatts of power needed to support over one million XPUs in one physical building. Scale-across networking helps overcome these challenges by enabling multiple distributed data centers (and their XPUs) to be interconnected across different locations and power grids to form a computational super-cluster.
Scale-across requirements: high capacity and low latency
High capacity and low latency are two of the most desirable attributes for scale-across networking. The largest AI and cloud providers want to fully load the C and L bands across hundreds of fiber pairs to deliver petabits of interconnect capacity. Scale-across networking is a key driver behind increasing fiber counts in new fiber builds. While 288 fiber pairs were common, ultra-high fiber count deployments with up to 3,456 pairs are becoming more prevalent.
Low latency is also critical for scale-across networking. The vast majority of the large language models we use today are trained utilizing synchronous training. With synchronous training, all XPUs in the cluster are assigned data in parallel and wait for all other nodes to complete their respective computation before aggregating updates. This means a single XPU delay can cost time and money. Synchronous training can limit the distance between data centers for scale-across networking to hundreds of kilometers. However, AI and cloud providers are continuously innovating, including expanding the use of asynchronous training techniques, which can relax latency requirements and enable deployments across thousands of kilometers.
Key optical technologies for scale-across
To address the needs of high-capacity, low-latency scale-across networks, the optical industry is also innovating in multiple areas simultaneously, including:
- Coherent pluggables. AI and cloud providers are rapidly adopting 800ZR+ZR+pluggables due to their high performance, small footprint and lower power consumption. For scale-across applications, 800G ZR/ZR+ pluggables are commonly hosted in backend switches/routers although thin transponders provide an alternative deployment option.
- High-capacity optical line system terminals. High port count, direct-attach ROADMs such as the 1830 GX RD66 can multiplex 64 or more wavelengths onto a fiber to enable 50-75 Tb/s using a single sled. Alternatively, fixed-filter solutions, such as the 32-port C-band only OMD32, cost-effectively multiplex 25-38.4 Tb/s of transmission capacity onto a fiber.
- Multi-rail inline amplifiers (ILAs). As ILA huts are space and power constrained, amplifying hundreds of fiber pairs every 50-100 kms can be challenging. Nokia’s multi-rail ILA enables in-line amplification of 160 fiber pairs per rack, a 40-fold increase in density compared to legacy ILAs and an 8x improvement compared to today’s state-of-the art conventional ILAs.
- Hollow-core fiber (HCF). While still relatively expensive and early in terms of mass commercialization, hollow-core fiber delivers 30% less propagation delay than today’s single-mode fiber. Looking ahead, HCF can be beneficial to scale-across applications by extending the practical distance between data centers by 40-50% while delivering similar latency results as single-mode fiber.
Why scale-across networking matters for AI
Scale-across networking is becoming essential to the next wave of AI infrastructure. As XPU clusters approach one million nodes and stretch across multiple data centers, optical innovations in coherent pluggables, optical line systems and the fiber transmission medium are critical to scaling AI factories and maximizing the business value of the AI supercycle.








