Building a new webscale management architecture for data center switching

For a very long time, the slow pace of change in the hardware-dominated world of networking put the emphasis on stability and longevity. We were taught that the best architectures were those that lasted forever. But we now live in the ever-flexible, rapidly scaling world of software and cloud services. In this webscale world, inflexible network management architectures are a liability. Evolution and adaptation are now essential attributes for survival and success.
There’s some kind of life-relevant lesson in all this, but I’ll leave that for the more philosophically minded to ponder. Suffice it to say that openness, extensibility and innovation are the founding principles of the webscale world. In this post, I want to look at what this means for managing data center networks and the implications for the new breed of network management tools.
Nokia worked with some of the industry’s largest cloud builders to evolve data center switching fabrics to bring webscale innovations to the mass market. Read our blog - Ushering in a new era of data center switching which covers the motivations for our approach
Challenges of traditional NOS architecture
To fully embrace webscale ideologies, you need to entertain their philosophy on change - frequent, incremental, automated. Dealing with this kind of incremental change in a monolithic fashion was a non-starter, but exposing fragmented applications to the management plane simply pushed the burden to operations.
In setting out to build these new webscale management tools, the vision we started with was clear. Give applications the ability to simplify their own internal schemas around data modeling languages, and then expose these schemas directly for consumption by northbound interfaces; in other words, any object, any interface. This provides deep visibility right into the heart of the system state and allows northbound applications to make API choices based on their functional requirements, rather than on which data they’re able to see.
In terms of deep visibility into the system state, the first issue was telemetry: Simple Network Management Protocol (SNMP) and command line interface (CLI) text scraping have served their purpose. Besides their cumbersome overhead, the bottom line is that the modern intent-based management layer needs information faster than they can provide. Implementing telemetry in this way is like looking in the rear-view mirror when driving only to see what you have passed rather than what you are just passing.
Next on the list, we needed to stop bolting things onto an obsolete, inflexible management architecture. In the beginning, proprietary APIs helped to support the old management layer, but this approach doesn’t scale; interoperability dependencies and integration issues started to pile up. What we needed was a blank slate on which we could build an architecture that was as open and transparent as the webscale world of applications it supports.
NETCONF (Network Configuration Protocol) and RESTCONF (RESTful Configuration Protocol) were the industry’s first recognition that we needed to move away from proprietary APIs towards a world of openness and extensibility — a model-driven world. But, although NETCONF and RESTCONF did make the first forays into automation possible, their implementations were typically skin-deep. The internal schemas of the infrastructure they attempted to expose remained opaque and unreadable, therefore untouched and non-extensible.
The traditional approach to these internal device schemas has been to make them largely inaccessible and mostly unchanging to the rest of the management system. As we have moved up through the network layers, we have created interfaces — many interfaces — between layers to help them talk to each other. But each interface is an abstraction, a simplification of the functionality it represents. In other words, something is always lost in translation.
It all becomes a bit like that old children’s game of telephone using tin cans and string. By the time the message moves around the room, it usually bears little resemblance to the original, sometimes with hilarious results. As we pivot to a model-driven world, the inefficiencies of all these interfaces aren’t nearly so funny. The inefficiencies add performance and visibility issues, which are exacerbated by the limits of specific northbound interfaces and the subsequent need to employ multiple interfaces just to achieve sufficient coverage.
So, the network needs to change, evolve, and do so at the pace of the application world - how do we represent an ever-changing network with an unchanging schema?
Building the NOS for true openness and ease of use
To represent an ever-changing network requires a different approach to architecture that is driven by the needs of model-driven management. Let the applications define and declare their own schemas. This will enable them to retrieve and expose the fine-grained detail on the system state that they actually need to function. They can then, in turn, react rapidly to change, interact with other applications over gRPC, and manipulate the configuration of the system to achieve a desired state, all using push-based streaming telemetry to keep northbound clients up to date.
If properly executed, this modern NOS should be able to support any object on any interface. We call this “building for openness”. It means consciously deciding at every turn to implement the architecture, so it is open, extensible and most important, visible and consumable. Unlike a traditional NOS, the architecture of a modern open NOS needs to enable management clients to have deep visibility into the network in real-time to constantly monitor and react to potential problems before they cause an outage.
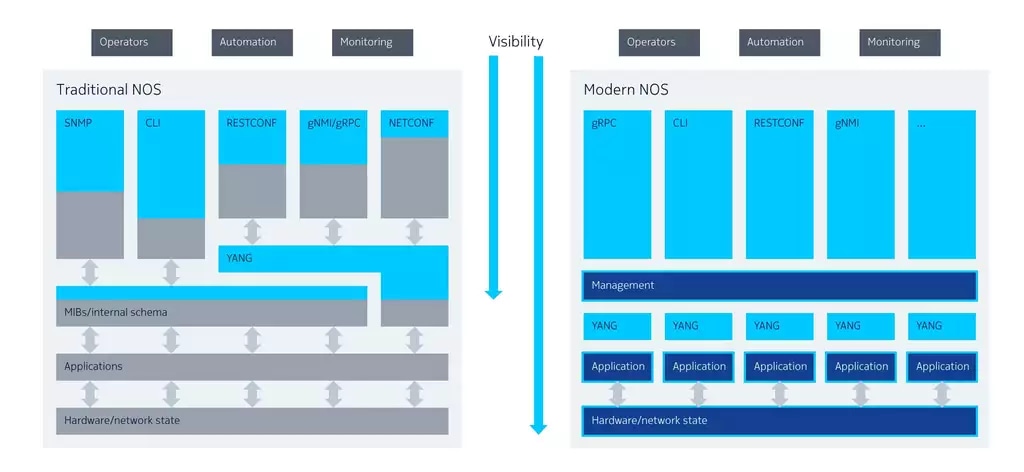
Critically, building for openness also means that extensibility cannot depend on the vendor. In a modern, open NOS, anyone, and especially, the operator, must be able to internally develop and deploy solutions to meet their customers’ needs, or react to operational demands.
The mantra is simple: be more agile, merge changes frequently, drive change using automation, and validate the end state using the management stack. The open system architecture allows the deployment of workflows or applications directly on the network, consuming previously idle CPU cycles, drawing insights locally, and performing actions immediately — and all of this is powered by an architecture purpose-built for model-driven management.
The final requirement is to build a robust development environment for network applications that supports a wide array of programming languages. This is the key to ensuring that it becomes a platform for innovation, where the network is an enabler, not an inhibiter that makes the operator dependent on the release schedules of the equipment vendor. The application world thankfully has solved this problem for us, with the use of gRPC/protocol buffers and their like, allowing applications to compile and create bindings for Nokia or user-created services. This allows application developers to use the language of their choice, rather than that the vendor decides.
Conclusion
In the past, network operating systems were closed, proprietary systems. This served the industry well in a time when most hardware platforms were also proprietary systems. Open APIs such as gNMI (gRPC Network Management Interface) and RESTCONF are a first step towards openness from vendors, but they miss the fact that open APIs into a black box address only one level of complexity. True openness can only be accomplished if it is designed at the heart of an architecture.
For additional information on our unique approach to NOS design, please watch our Networking Field Day 25 (NFD25) - Nokia SR Linux: An open, extensible and resilient NOS presentation and demo and listen to the Packet Pushers Podcast - Nokia SR Linux – A Hyperscaler NOS Designed For Everyone
Additional resources:




