Nokia Cloud Platform


Since the recently announced strategic partnership RedHat Openshift Container Platform (OCP) is the primary cloud infrastructure platform to develop, test and deliver Nokia’s core network applications and business applications, benefiting from its scalability, flexibility, and advanced orchestration capabilities.
Combining OCP with Nokia’s reference hardware and blueprint architecture via horizontal and vertical integration, we offer a TCO optimized solution, which is called the new Nokia Cloud Platform. Security hardening, automation, performance validation makes the platform ideal to host Nokia CNFs as workloads.
What are the benefits of our new Nokia Cloud Platform?
It provides a comprehensive set of key functionalities that are essential for Nokia Core CNFs. These functionalities encompass networking solutions, load balancing capabilities, robust ingress and egress control mechanisms, as well as ensuring high availability and seamless scalability of the core network applications.
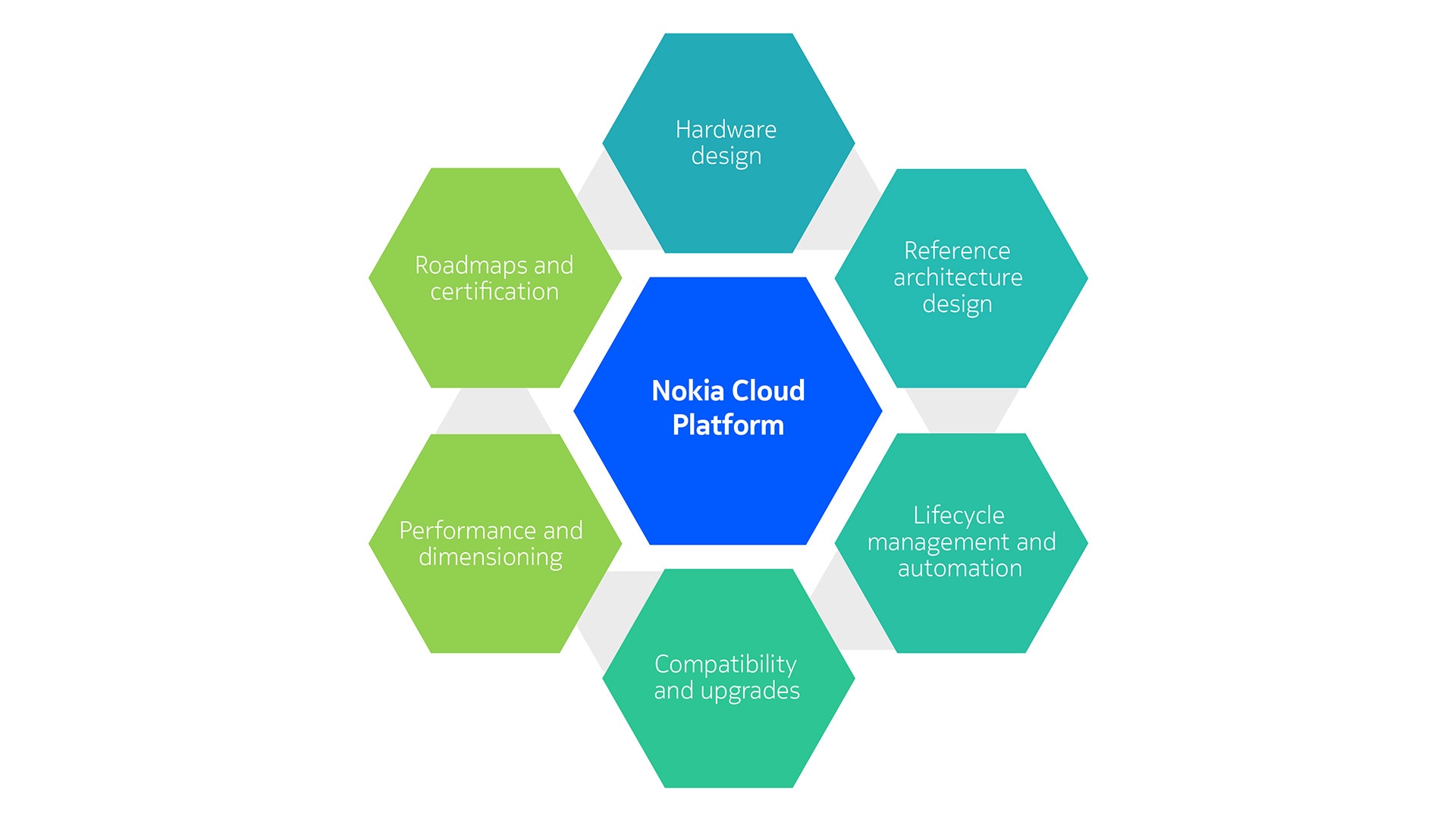

It is closely and early integrated with Nokia reference hardware. OCP releases are integrated and tested with hardware vendors' products. On top of that, Nokia end-to-end tests the reference hardware, networking fabric, CaaS configuration and management tools and automation, providing an extra layer of quality assurance.
OCP brings a robust security framework
- Security Context Constraints (SCCs) for pod-level permissions.
- Role-Based Access Control (RBAC) for granular permissions within the cluster.
- Secrets Management to securely store sensitive information.
- Network Policies for controlling pod-to-pod communications.
- Encryption for data at rest and in transit.
- Image Scanning and Signing to ensure only trusted images are used.
- Centralized Logging and Monitoring for security events.

How NCP is leveraging Kubernetes?
By leveraging the Kubernetes Operator Framework, NCP empowers organizations to streamline and automate the complexities of day-2 operations. It reduces manual intervention, enhances application reliability, and allows administrators to focus on strategic tasks while benefiting from efficient automation provided by operators. This approach contributes to the agility and efficiency of managing containerized applications in production environments.
Nokia Cloud Platform includes OpenShift Container Platform (OCP) seamlessly and comprehensively integrated to Nokia's Cloud Native Network Functions (CNFs). This integration will yield a cohesive and reliable core network solution that not only meets, but exceeds expectations in terms of robustness, security, and high performance.
Related solutions and products
Product
Automate hybrid cloud lifecycle operations
Product
Get a VNFM for OpenStack- and VMware-based virtual machines
Learn more about cloud

Article

Video


Video
Core Networks - 2023 and beyond


Video
Nokia Core TV series #33: Digital twin for optimizing CNF configurations

Customer success

Customer success


Video
Nokia Core TV series #25: Intent based config automation


Video
Nokia Core Talk: Quest for operational efficiency with Elisa
Latest news
Please complete the form below.
The form is loading, please wait...
Thank you. We have received your inquiry. Please continue browsing.