AI data center networking
Build unconstrained large scale AI fabrics to exceed the performance, scale, and reliability demands of current and future AI applications.

What is AI data center networking?
Data center networks that run AI applications must approach networking in a different way. AI training and inferencing are not only compute-intensive but they have dramatically augmented the performance criteria of the networks that needs to support them. AI data center networking applies super high speed and scalable switches, an open, programmable and highly reliable NOS, along with AI-enabled network automation to meet and exceed these requirements.

Data center networking for AI era
Welcome to a new era of extreme networking—powered by Nokia’s 7220 IXR-H6 switches. Combined with advanced automation and AIOps, Nokia unleashes cloud providers, and enterprises to build scalable, high-performance fabrics for the most demanding workloads.
Back-end and front-end networks for AI workloads
Organizations need well-designed data center networks to tackle the challenging demands of AI workloads. These networks must extend seamless, reliable connectivity across the AI infrastructure and deliver the best possible performance for every AI training and inference task.
The back-end network is used to interconnect the high-value graphics processing unit (GPU) resources required for high-computation tasks such as AI training, AI inference or other HPC workloads. It delivers lossless, low-latency and high-performance connectivity for AI training compute and dedicated storage resources.
The front-end network supports connectivity for AI workloads, general-purpose workloads (non-AI compute) and the management of AI workloads. In the context of AI inference, the front-end delivers fast response times and proximity to the end user.
In both cases, it’s essential for organizations to control—and, ideally, reduce—their cost and power use as they deploy networks to meet these new demands.

Video
Switches for unmatched data center performance
Ultra Ethernet Consortium (UEC)
More and more organizations are choosing Ethernet technologies to build back-end networks for AI workloads. Ethernet already dominates front-end network designs. The work of the Ultra Ethernet Consortium (UEC) will bring enhancements that make Ethernet the best choice for AI network infrastructures.
UEC is working to deliver an open, interoperable, high-performance, full-communications-stack architecture based on Ethernet to meet the growing network demands of AI and HPC at scale.
UEC members, including Nokia, aim to leverage the ubiquity, performance curve and cost benefits of Ethernet to evolve the legacy RDMA over Converged Ethernet (RoCE) protocol with Ultra Ethernet Transport (UET). This modern transport protocol is designed to enhance network performance to meet the requirements of AI and HPC applications while preserving the advantages of the Ethernet/IP ecosystem.

How can Nokia help you build a highly performant and scalable AI data center network?
The Nokia Data Center Fabric solution provides the reliability, simplicity and flexibility you need to build and deploy network infrastructures that can meet the requirements of current and future AI workloads.
Modular and fixed configuration platforms
Our solution includes a comprehensive portfolio of modular and fixed-configuration hardware platforms for implementing high-performance leaf–spine designs. You can use our platforms to build high-capacity, low-latency and lossless backend networks that can efficiently handle demanding AI training workflows. We also offer platforms in many different form factors to support frontend network designs that will interconnect your AI inference compute, non-AI compute and shared storage resources.
A powerful and proven network operating system
Our data center hardware platforms run on the Nokia SR Linux network operating system (NOS). SR Linux opens the NOS infrastructure with a unique architecture built around model-driven management and modern interfaces. It is designed for reliability and quality, ready for automation at scale, and easy to customize and extend.
SR Linux provides congestion management and traffic prioritization capabilities that let you deliver lossless Ethernet networking. It also supports high-performance AI infrastructures with superior telemetry, manageability, ease of automation and resiliency features.
Fabric management and automation toolkit
Nokia Event-Driven Automation (EDA) is a modern data center network automation platform that combines speed, reliability and simplicity. It makes network automation more trustable and easier to use wherever you need it, from small edge clouds to the largest data centers.
With EDA, you can automate the entire data center network lifecycle from initial design to deployment to daily operations. This allows you to ensure reliable network operations, simplify network management and adapt to evolving demands.
EDA offers a range of flexible AIOps capabilities through its natural language interface. Operators simply use this interface to ask an operational question in the areas of troubleshooting, root cause analysis, remediation support, and more, and through an Agentic AI process, the system responds.
Data center interconnectivity
Some companies may implement their own training infrastructures. Others may prefer to use AI platforms and associated services from large cloud providers, an approach known as GPU as a service (GPUaaS) or public AI.
Inferencing models that need low-latency end-user access are typically run in enterprise edge locations in private AI infrastructures. Batch-mode and global-scale inferencing models are better suited for implementation in public AI frameworks.
We offer a comprehensive solution that makes it easy to interconnect AI infrastructures between data centers and across the WAN. The Nokia Optical Data Center Interconnect (DCI) and Nokia Data Center Gateway (DCGW) solutions let you provide reliable, high-performance interconnection across AI infrastructure domains. They can help you meet evolving distributed AI connectivity requirements so you can serve AI models at the edge of the network, closer to end users.


Application note
Networking for AI workloads

Learn about networking for AI workloads



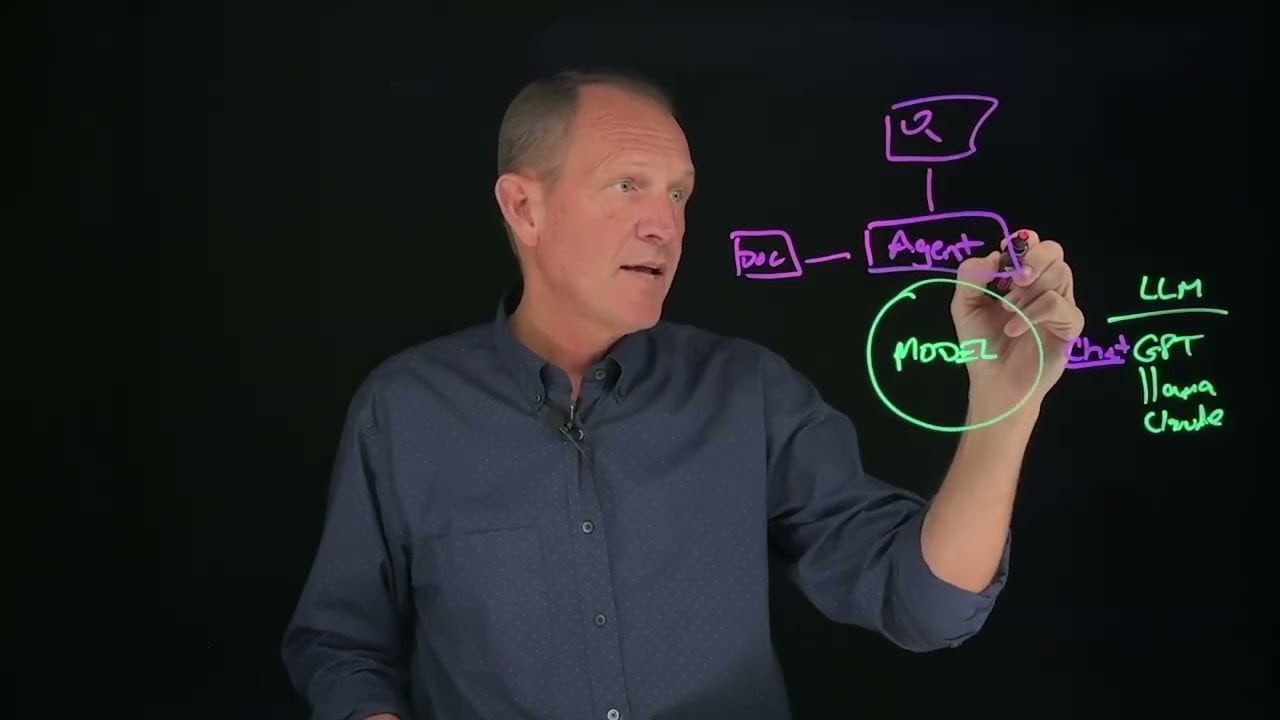
Nokia TechTalks in 10 - Networking for AI - Introduction

Nokia TechTalks in 10 -- Networking for AI - Training
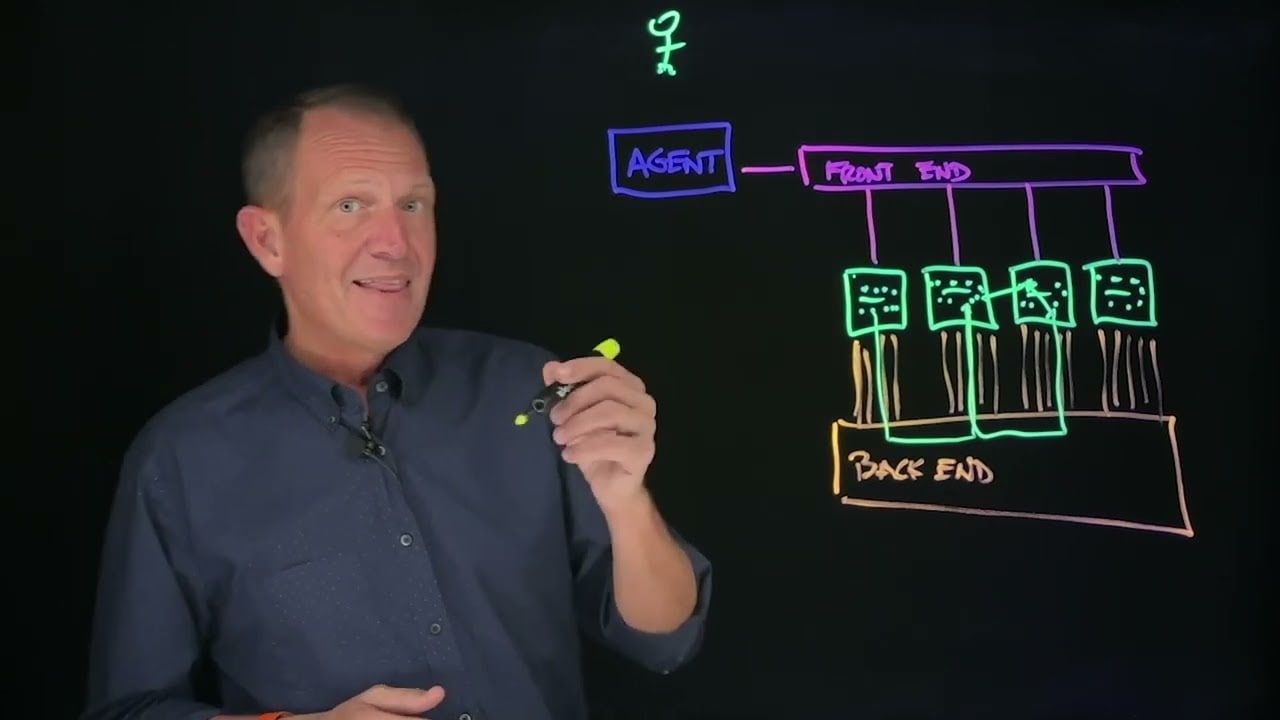
Nokia TechTalks in 10 - Networking for AI - Inference
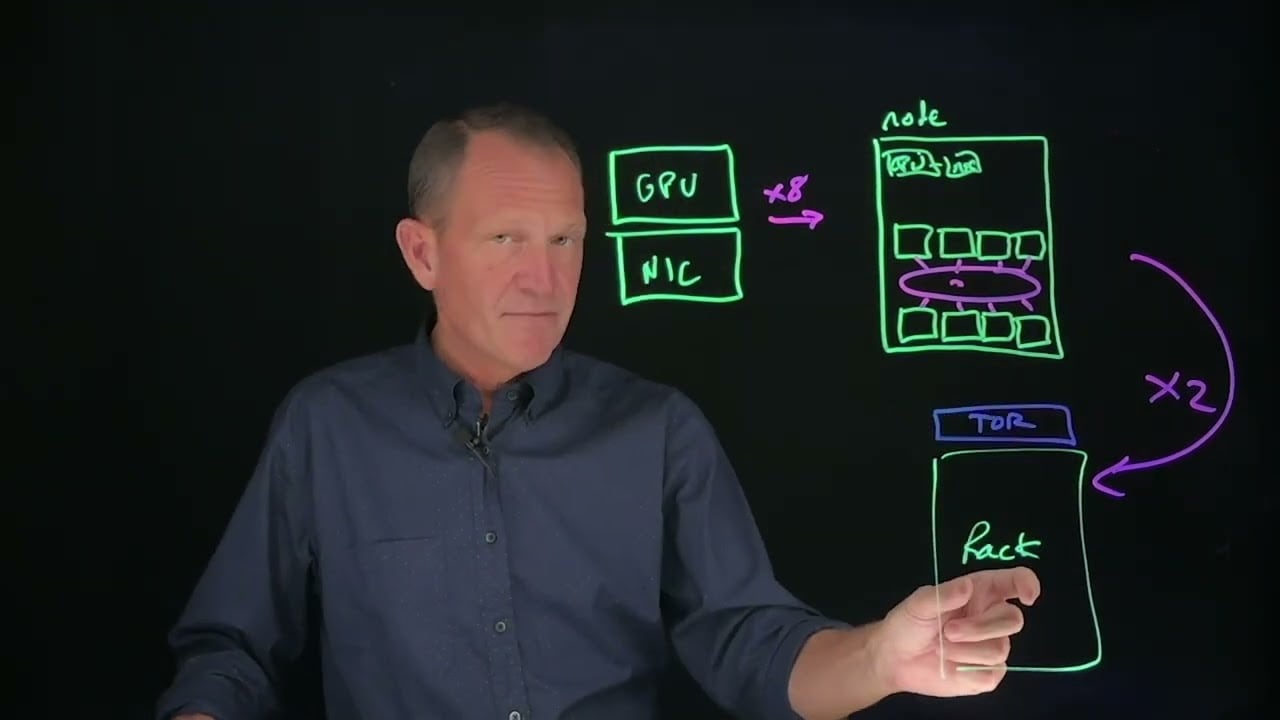
Nokia TechTalks in 10 - Networking for AI - Hardware

Nokia TechTalks in 10 - Networking for AI – Protocols & communication

Nokia TechTalks in 10 - Networking for AI – Ethernet and congestion control

Nokia TechTalks in 10 - Networking for AI – Futures and the work of the UEC
Discover our related networking solutions for AI workloads
Solution
Data Center Fabric
Bring new levels of reliability, simplicity and adaptability to your data center switching and cloud infrastructures.
Product
Event-Driven Automation
Automate your data center network and eliminate human error.
Solution
Data Center Gateway (DCGW)
Learn how the Nokia Data Center Gateway can help you optimize data center connectivity, performance, scalability and reliability.
Solution
Optical DCI
Maximizing network infrastructure ROI in the era of AI.
Related topics
Networks for AI, with AI
Build AI-powered networks that meet the demands of AI applications.

IP networks and AI
IP networks built for AI, powered by AI.

Critical connectivity for modern data centers
Learn more about the critical role of the network in data center evolution to enable the cloud transformation in the AI era.
Learn more

Article

Article

Blog

eBook

Blog

Blog

Solution brochure

Article
Latest news
Ready to talk?
Please complete the form below.
The form is loading, please wait...
Thank you. We have received your inquiry. Please continue browsing.
The Nokia Data Center Fabric solution provides the reliability, simplicity and flexibility you need to build and deploy network infrastructures that can meet the requirements of current and future AI workloads.
Modular and fixed configuration platforms
Our solution includes a comprehensive portfolio of modular and fixed-configuration hardware platforms for implementing high-performance leaf–spine designs. You can use our platforms to build high-capacity, low-latency and lossless backend networks that can efficiently handle demanding AI training workflows. We also offer platforms in many different form factors to support frontend network designs that will interconnect your AI inference compute, non-AI compute and shared storage resources.
Most AI workloads are more compute-intensive than workloads created by traditional computing applications. Many also involve the exchange of massive volumes of data. All require fast processing to deliver the experiences users expect.
There are two main types of workloads associated with AI models. AI training involves data collection, model selection, model training and model deployment. Job Completion Time (JCT) measures the interval from job start to final checkpoint write. JCT depends on compute efficiency, storage throughput, cluster orchestration, and especially network performance. Designing low-latency, loss-free networks is critical for efficient AI training.
Inferencing is the process by which an AI model generates responses for an end user or machine via an AI agent. When the AI agent receives a request, the GPUs collaborate exchanging intermediate results to produce the final answer. As the model generates output, it creates “tokens” in real-time until the complete response is delivered. Inference performance is measured in tokens per second (TPS).
A network designed for AI can look a lot different to the more traditional data center network and include various parts that operate together to deliver AI services.
Frontend network
The part of the infrastructure that manages how external systems and users interact with the AI workloads. It acts as the gateway between the outside world and the internal compute resources. Backend “scale-out” networks
High-performance infrastructures designed to connect multiple GPUs within a large cluster and across different servers, enabling distributed AI workloads to run without.
Backend “scale-up” networks
High-bandwidth, low-latency infrastructures that connect GPUs within a single server or tightly coupled cluster to accelerate AI training and inference.
Backend “scale-up” networks
High-bandwidth, low-latency infrastructures that connect GPUs within a single server or tightly coupled cluster to accelerate AI training and inference.
InfiniBand has set the benchmark for AI back‑end networking, but its closed, proprietary nature has opened the door for Ethernet to become the preferred, future‑proof solution for GPU‑based AI training and inference.
Why Ethernet?
• Broad ecosystem: Switches, NICs, test gear, SFPs, and open‑source management tools.
• Rapid innovation: Continual upgrades in protocols, link speeds, optics, and cabling.
• Universal familiarity: Widely understood and easily adopted by engineering teams.
• Scalable with IP: Proven to expand across massive, super‑scale networks.
• Open, multivendor: Flexible choice of vendors and components.
The Ultra Ethernet Consortium (UEC) is a collaborative organization focused on advancing Ethernet technology to meet the demands of high-performance computing (HPC) and artificial intelligence (AI) applications. It released its first specification 1.0 in June 2025.
Key objectives include:
Optimizing Ethernet for High Performance: The consortium focuses on enhancing Ethernet to exceed the performance of AI and HPC workloads.
Improving Network Functionality: UEC specifications are designed to bridge gaps in current Ethernet capabilities, which are critical for modern workloads.
Backward Compatibility: Ensuring that new developments maintain compatibility with widely-deployed APIs while defining new APIs optimized for future workloads.