Physical AI: Redefining RAN and telco monetization

The world is witnessing a new revolution, comparable in scale to the Industrial, Internet, and mobile broadband revolutions. Artificial intelligence has been unleashed by large language models and the rapid growth of applications that depend on them. Most mobile devices already support a wide range of AI-driven applications, such as scene recognition, document generation, text-based chat, voice conversations and image and video generation and editing. These new applications will inevitably affect mobile traffic patterns.
A recent Nokia report analyzing more than 50 AI applications highlights several trends, including a shift toward higher uplink traffic, overall traffic growth, and increasing sensitivity to latency for conversational voice and chat applications. While these impacts are becoming clearer, the more consequential question is whether emerging trends, particularly Physical AI, require a fundamental change in how traffic is handled in the radio access network (RAN).
A brief history of major radio access design changes
Mobile networks are designed to support a wide range of traffic types, from high volume video streaming to low latency voice to low volume messaging. Historically, this versatility has allowed operators to meet new demands primarily by adding capacity. In practice, many advanced quality-of-service (QoS) features remain underutilized, with best-effort delivery serving most traffic, supported by some degree of overprovisioning. In other words, “throwing bandwidth at the problem” has proven remarkably resilient.
There are, however, precedents where capacity scaling alone was not sufficient.
- The first came with the shift from circuit-switched voice to packet-based IP traffic. Early mobile systems were optimised for deterministic voice patterns, where similar sized data blocks arrived at regular intervals. IP traffic introduced variable packet sizes and timing, making circuit-style resource allocation inefficient and driving a shift toward shared channels and more sophisticated scheduling.
- A second inflection point came with IoT. Packet sizes became so small that conventional Internet oriented radio designs were inefficient, while coverage requirements expanded to deep indoor environments (e.g. in basements where various types of meters are typically installed). This led to purpose-built narrowband technologies such as LTE-M and NB-IoT.
By contrast, the growth of video streaming and Web 2.0 did not require architectural change. Capacity expansion was sufficient.
Does AI traffic require a design shift?
Returning to AI: does it require a fundamentally different approach?
For current AI applications, the answer is largely no. But looking ahead to Physical AI, where models running in edge data centers assist or control machines, the answer may be yes.
Physical AI - generally defined as the integration of artificial intelligence into physical machinery, enabling robots and autonomous systems to perceive, reason and interact with the real world in real-time - introduces the possibility that large‑volume uplink video with strict latency requirements will become a meaningful part of mobile traffic, creating both a design challenge and a monetization opportunity.
The core premise for our thesis is that Physical AI will rely on low latency videos to enable real-time control. While the machines or robots will perform most functions locally, there will be situations where they need to rely on more powerful models or human operators to provide remote control via the network. For example, driverless taxis may require remote assistance in unexpected scenarios; service robots may need guidance in complex environments; drones may depend on real‑time video analysis at the point of delivery; and field workers using AR may require timely visual instructions. In all these cases, the network must deliver fresh video information with low and predictable latency.

This is where Physical AI diverges from conventional video streaming. Traditional video streaming can rely on buffering to absorb network delays. For Physical AI, buffering is not an option. Video frames must arrive within a tight window to remain useful. This shifts the focus from average speed to consistency: how often packets arrive too late to matter.
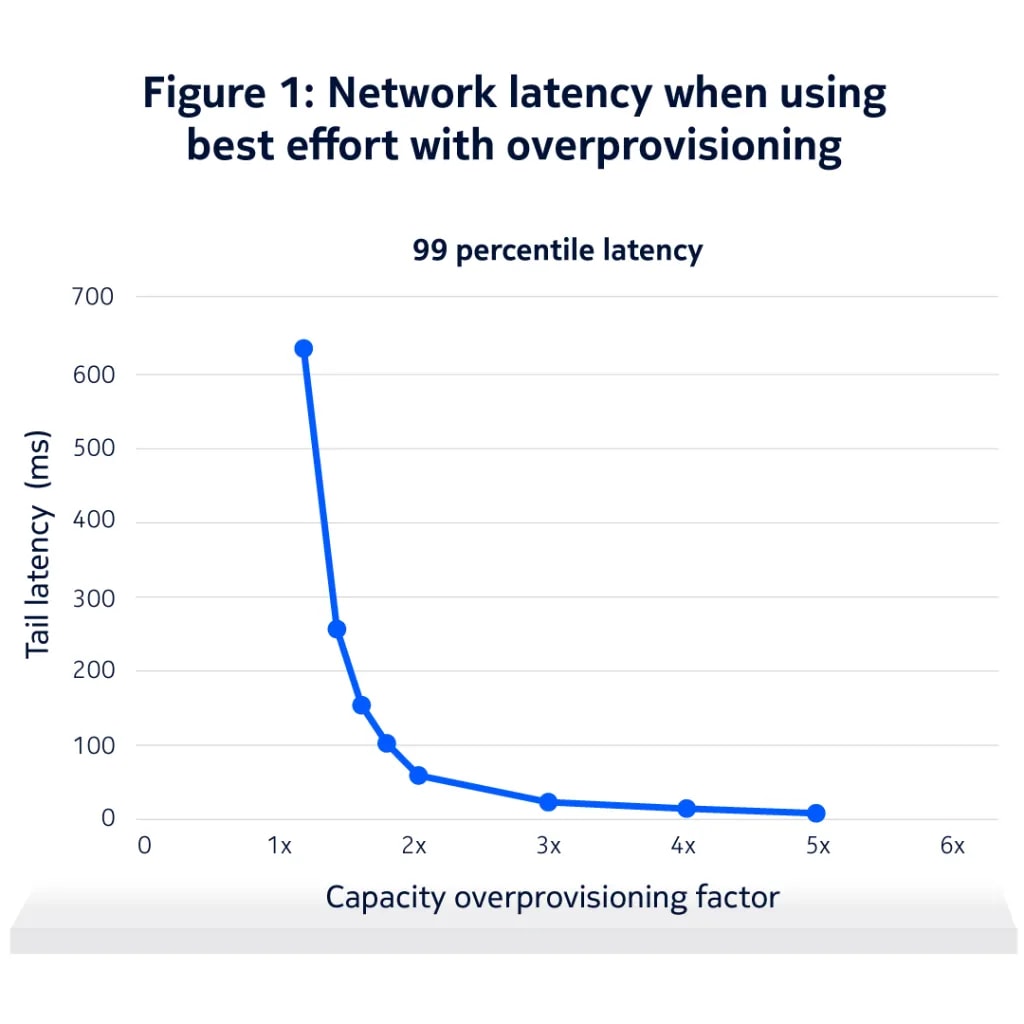
Figure 1 shows that when traffic is handled as best effort, keeping latency consistently low requires a large margin of unused capacity. For Physical AI video, maintaining end to end latency of around 20 milliseconds for almost all packets can require provisioning three to four times the average uplink video rate.
This is not an issue for video streaming, where buffering absorbs delay, or for conversational voice, where traffic volumes are low.
Physical AI video combines strict latency requirements with much higher data volumes. As more devices are added, the capacity that must be reserved grows rapidly. Beyond a small number of sessions per cell, this approach becomes costly and difficult to scale, making it a key driver for rethinking how low latency traffic is handled in the network.
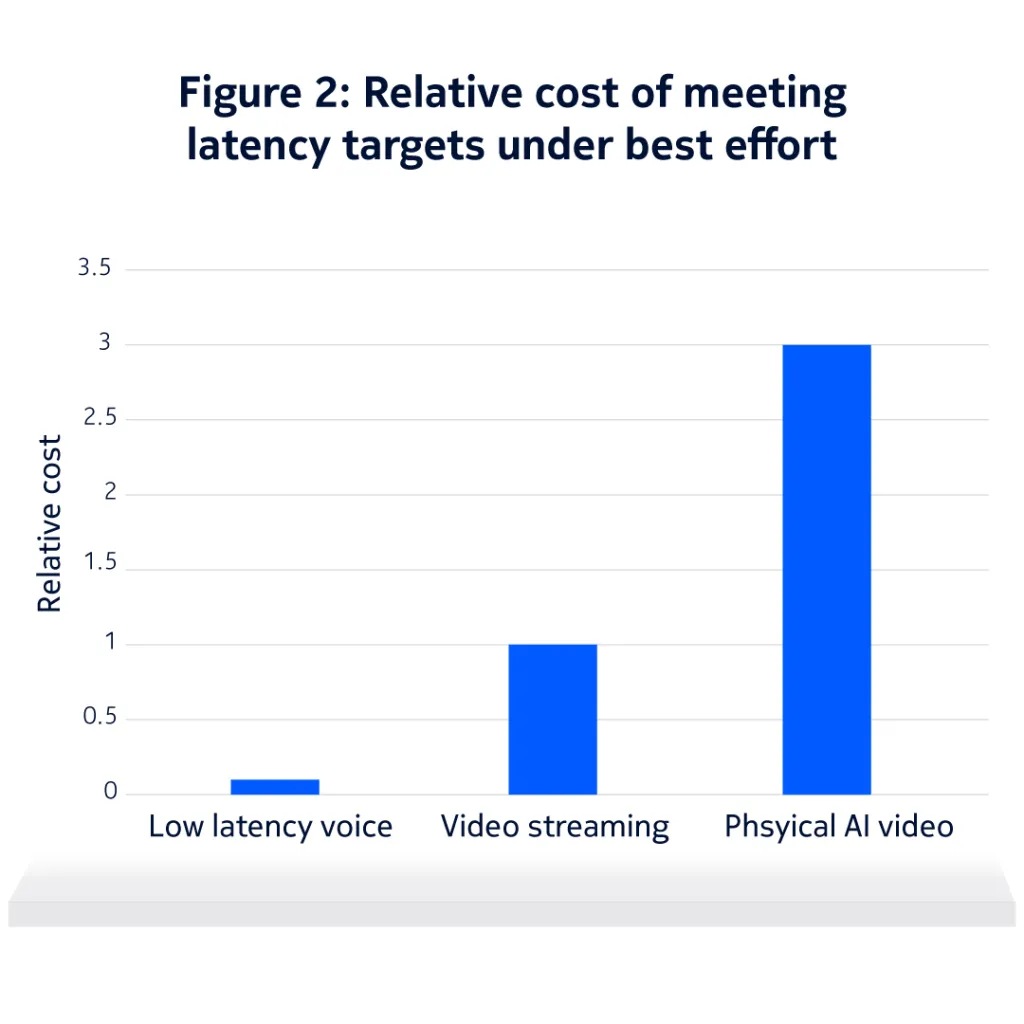
Figure 2 compares the relative network cost of three traffic types carried as best effort: conversational voice, video streaming, and low latency Physical AI video, assuming the same session duration.
Conversational voice requires low latency, but the data rate is very low, so the amount of additional capacity needed has a limited cost impact. Video streaming uses much higher data rates, but it does not require strict latency guarantees, allowing the network to operate efficiently without significant overprovisioning.
Low latency Physical AI video requires both higher data rates and tight latency guarantees. As a result, the capacity required per session increases sharply. Even when the nominal video rate appears modest (i.e. 1 Mbps), the need for consistent low latency drives a much higher effective cost.
Implications for the future of networks and Physical AI applications
Reducing the cost of supporting Physical AI traffic will require changes at three levels: applications, networks, and service models.
At the application level, not all video needs to be delivered with the same urgency or level of detail. When video is consumed by an AI rather than a human, it may be sufficient to transmit only the information required for the control task. This approach, often referred to as semantic or token-based communication, can significantly reduce the amount of traffic that needs strict latency guarantees. Video intended for human viewing (e.g. for verification or later review), can be delivered with lower priority. Applications may also structure information in layers so that critical elements are delivered first during congestion. New interfaces where applications can indicate semantic priority to the network should be included in the network design.
At the network level, existing QoS and network slicing capabilities can be used more effectively. This includes better visibility into packet importance and timing, enabling prioritization of fresh, critical information. Clearer signaling can also support controlled packet dropping and protection, improving reliability without treating all traffic equally.
At the service and monetisation level, supporting low latency Physical AI video incurs higher network cost than best effort delivery. Scaling sustainably will require differentiated connectivity with defined latency and reliability targets, along with automated mechanisms to establish and verify service level agreements.
Summary
Mobile networks have historically accommodated new applications through steady improvements in capacity and reliability, without major changes to the network design. Most AI-driven traffic will likely follow this pattern. Physical AI could be an exception.
If large volume, low latency uplink video becomes common, best effort delivery with overprovisioning will no longer be sustainable. The cost of maintaining consistently low latency rises too quickly as traffic volumes grow, making Physical AI traffic fundamentally different from previous waves of mobile video and data growth. Other use cases such as mobile compute offloading and federated learning may further accelerate this shift.
Meeting low latency requirements at scale and at reasonable cost will require more deliberate and differentiated traffic handling. Incorporating traffic semantics can improve efficiency and enable new monetization models based on guaranteed performance. Capabilities such as QoS differentiation and network slicing, which have existed for years but seen limited practical use, are likely to become essential.
To support this transition, networks must provide stronger tools for service differentiation and reliable mechanisms to establish and validate service level agreements. They must also evolve toward more programmable radio access platforms, enabling operators to scale efficiently as Physical AI and other latency-sensitive workloads emerge.







